Evaluating Agents in Real Time

Demo
This blog is built on top of

📈 GitHub Stars Over Time
Real Time Evaluation
- Math Agent not adhering to Math Topic: (
topic_adherence=0)- Query on Taylor Swift is not Math related
- Math Agent adhering to Math Topic on 2nd Human Query: (
topic_adherence=0.5)- Query
what is 1+1is Math related
- Query
Human Annotation
- Math Agent uses
addtool to answerwhat is 1+1query:tool_call_accuracy=1
Introduction
When building agentic systems, it's often unclear whether a tweak has a net positive or negative effect. How can you determine this to iterate in the right direction?
- Can this evaluation be automated in real time?
- Or must it be done manually with human annotations after the fact?
Ragas

Topic Adherence
Topic Adherence measures how well an agent sticks to the intended topic using familiar metrics:
- Precision
- Recall
- F1 score
The formula shown below calculates precision:
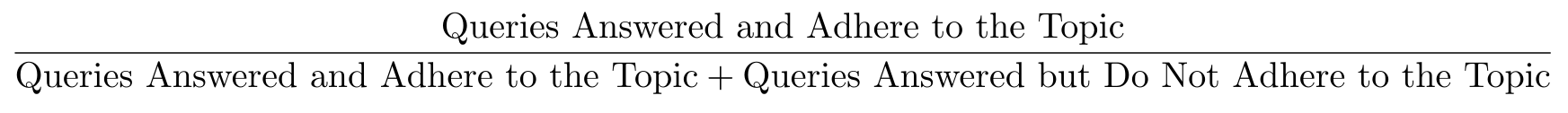
Combined with the provided Ragas prompt, this helps assess how accurately an agent follows a topic.
Given an interaction between Human, Tool and AI, extract the topics from Human's input.
Please return the output in a JSON format that complies with the following schema as specified in JSON Schema:
{"properties": {"topics": {"items": {"type": "string"}, "title": "Topics", "type": "array"}}, "required": ["topics"], "title": "TopicExtractionOutput", "type": "object"}Do not use single quotes in your response but double quotes,properly escaped with a backslash.
--------EXAMPLES-----------
Example 1
Input: {
"user_input": "Human: Can you provide me with details about Einstein's theory of relativity?\nAI: Sure, let me retrieve the relevant information for you.\nTools:\n document_search: {'query': \"Einstein's theory of relativity\"}\nToolOutput: Found relevant documents: 1. Relativity: The Special and the General Theory, 2. General Theory of Relativity by A. Einstein.\nAI: I found some documents on Einstein's theory of relativity. Which one would you like to know more about: 'Relativity: The Special and the General Theory' or 'General Theory of Relativity by A. Einstein'?\nHuman: Tell me about the 'General Theory of Relativity'.\nAI: Got it! Let me fetch more details from 'General Theory of Relativity by A. Einstein'.\nTools:\n document_retrieve: {'document': 'General Theory of Relativity by A. Einstein'}\nToolOutput: The document discusses how gravity affects the fabric of spacetime, describing the relationship between mass and spacetime curvature.\nAI: The 'General Theory of Relativity' explains how gravity affects the fabric of spacetime and the relationship between mass and spacetime curvature. Would you like more details or a specific explanation?\nHuman: That's perfect, thank you!\nAI: You're welcome! Feel free to ask if you need more information."
}
Output: {
"topics": [
"Einstein's theory of relativity",
"General Theory of Relativity"
]
}
-----------------------------
Now perform the same with the following input
Input: (None)
Output:
See the demo above.
Agent Goal Accuracy
Agent Goal Accuracy Without Reference evaluates whether the agent successfully reaches its intended goal. This is done using a dedicated prompt from Ragas.
Given an agentic workflow comprised of Human, AI and Tools, identify the user_goal (the task or objective the user wants to achieve) and the end_state (the final outcome or result of the workflow).
Please return the output in a JSON format that complies with the following schema as specified in JSON Schema:
{"properties": {"user_goal": {"description": "The task or objective the user wants to achieve.", "title": "User Goal", "type": "string"}, "end_state": {"description": "The final outcome or result of the workflow.", "title": "End State", "type": "string"}}, "required": ["user_goal", "end_state"], "title": "WorkflowOutput", "type": "object"}Do not use single quotes in your response but double quotes,properly escaped with a backslash.
--------EXAMPLES-----------
Example 1
Input: {
"workflow": "\n Human: Hey, book a table at the nearest best Chinese restaurant for 8:00pm\n AI: Sure, let me find the best options for you.\n Tools:\n restaurant_search: {'cuisine': 'Chinese', 'time': '8:00pm'}\n ToolOutput: Found a few options: 1. Golden Dragon, 2. Jade Palace\n AI: I found some great options: Golden Dragon and Jade Palace. Which one would you prefer?\n Human: Let's go with Golden Dragon.\n AI: Great choice! I'll book a table for 8:00pm at Golden Dragon.\n Tools:\n restaurant_book: {'name': 'Golden Dragon', 'time': '8:00pm'}\n ToolOutput: Table booked at Golden Dragon for 8:00pm.\n AI: Your table at Golden Dragon is booked for 8:00pm. Enjoy your meal!\n Human: thanks\n "
}
Output: {
"user_goal": "Book a table at the nearest best Chinese restaurant for 8:00pm.",
"end_state": "A table is successfully booked at Golden Dragon (Chinese restaurant) for 8:00pm."
}
-----------------------------
Now perform the same with the following input
Input: (None)
Output:
Tool Call Accuracy
Tool Call Accuracy requires Human Annotation as seen in the demo above. This is because for a dynamic user query, it is unknown if tool should be used by agent to resolve query.
General Purpose Metrics
General Purpose Metrics such as correctness and maliciousness are self explanatory. Below are Ragas' prompts:
Is the submission factually accurate and free from errors?
Is the submission intended to harm, deceive, or exploit users?
Conclusion
The metrics discussed above help benchmark Agentic Systems to guide meaningful improvements:
-
If Tool Call Accuracy is low:
- The LLM may not understand when or how to use a tool.
- Consider prompt engineering or better tool usage instructions.
-
If Topic Adherence is low:
- The agent might be straying from its task.
- Introduce or refine guardrails (e.g., in a customer service domain) to keep it focused.